This post is part of my Game Math Series.
Also, this post is part 1 of a series (part 2) leading up to a geometric interpretation of Fourier transform and spherical harmonics.
Fourier transform and spherical harmonics are mathematical tools that can be used to represent a function as a combination of periodic functions (functions that repeat themselves, like sine waves) of different frequencies. You can approximate a complex function by using a limited number of periodic functions at certain frequencies. Fourier transform is often used in audio processing to post-process signals as combination of sine waves of different frequencies, instead of single streams of sound waves. Spherical harmonics can be used to approximate baked ambient lights in game levels.
We’ll revisit these tools in later posts, so it’s okay if you’re still not clear how they can be of use at this point. First, let’s start somewhere more basic.
Projecting a Vector onto Another
If you have two vectors  and
and  , projecting onto means stripping out part of that is orthogonal to , so the result is the part of that is parallel to . Here is a figure I borrowed from Wikipedia:
, projecting onto means stripping out part of that is orthogonal to , so the result is the part of that is parallel to . Here is a figure I borrowed from Wikipedia:
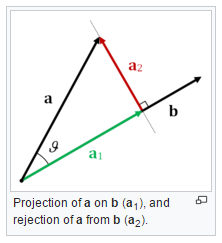
The dot product of and is a scalar equal to the product of magnitude of both vectors and the cosine of the angle ( , using the figure above) between the vectors:
, using the figure above) between the vectors:
![\[ \vec{a} \cdot \vec{b} = |\vec{a}| |\vec{b}| cos\theta \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-fce96a729e575b92fad0c0a45cc9cb38_l3.png "Rendered by QuickLaTeX.com")
Another way of calculating the dot product is adding together the component-wise products. If  and
and  , then:
, then:
![\[ \vec{a} \cdot \vec{b} = a_x b_x + a_y b_y + a_z b_z \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-f002ec6095d4bae621561b9d7ca32d5d_l3.png "Rendered by QuickLaTeX.com")
A follow-up to the alternate formula above is the formula for vector magnitude. The magnitude of a vector is the square root of the dot product of the vector with itself:
![\[ |\vec{a}| = \sqrt{a_x^2 + a_y^2 + a_z^2} = \sqrt{\vec{a} \cdot \vec{a}} \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-9b2868731ce0226592bca63a0d3f2800_l3.png "Rendered by QuickLaTeX.com")
The geometric meaning of the dot product  is the magnitude of the projection of onto scaled by
is the magnitude of the projection of onto scaled by  . Dot product is commutative, i.e.
. Dot product is commutative, i.e.  , which means that is also equal to the magnitude of the projection of onto scaled by
, which means that is also equal to the magnitude of the projection of onto scaled by  .
.
So if you want to get the magnitude of the projection of onto , you need to divide the dot product by the magnitude of :
![\[ |proj(\vec{a}, \vec{b})| = \dfrac{\vec{a} \cdot \vec{b}}{|\vec{b}|} = |\vec{a}| cos\theta \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-0994fb9878031c38f8649e53e12dfe7d_l3.png "Rendered by QuickLaTeX.com")
To get the actual projected vector of onto , multiply the magnitude with the unit vector in the direction of , denoted by  :
:
![\[ proj(\vec{a}, \vec{b}) = (\dfrac{\vec{a} \cdot \vec{b}}{|\vec{b}|}) \hat{b} = (\dfrac{\vec{a} \cdot \vec{b}}{{|\vec{b}|}^2}) \vec{b} = (\dfrac{\vec{a} \cdot \vec{b}}{\vec{b} \cdot \vec{b}}) \vec{b} \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-2cdfe25f6a724f5263407643823dc8f3_l3.png "Rendered by QuickLaTeX.com")
One important property of dot product is: if it’s positive, the two vectors point in roughly the same direction ( ); if it’s zero, the vectors are orthogonal (
); if it’s zero, the vectors are orthogonal ( ); if it’s negative, the vectors point away from each other (
); if it’s negative, the vectors point away from each other ( ).
).
For the dot product of two unit vectors, like  , it’s just
, it’s just  . If it’s 1, then the two vectors point in exactly the same direction (
. If it’s 1, then the two vectors point in exactly the same direction ( ); if it’s -1, then the two vectors point in exactly opposite directions (
); if it’s -1, then the two vectors point in exactly opposite directions ( ). So, in order to measure how close the directions two vectors point in, we can normalize both vectors and take their dot product.
). So, in order to measure how close the directions two vectors point in, we can normalize both vectors and take their dot product.
Let’s say we have three vectors: , , and  . If we want to determine which of and points in a direction closer to where points, we can just compare the dot products of their normalized versions, and
. If we want to determine which of and points in a direction closer to where points, we can just compare the dot products of their normalized versions, and  . Whichever vector’s normalized version has a larger dot product with
. Whichever vector’s normalized version has a larger dot product with  points in a direction closer to that of .
points in a direction closer to that of .
A metric often used to measure the difference between two data objects is the root mean square error (RMSE) which is the square root of the average of component-wise errors. For vectors, that means:
![\[ RMSE(\vec{a}, \vec{b}) = \sqrt{\frac{1}{3}((a_x - b_x)^2 + (a_y - b_y)^2 + (a_z - b_z)^2)} \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-635b8f32450bf0c5c27410241a9c351f_l3.png "Rendered by QuickLaTeX.com")
It kind of makes sense, because it is exactly the magnitude of the vector that is the difference between and scaled by  :
:
![\[ RMSE(\vec{a}, \vec{b}) = (\dfrac{1}{\sqrt{3}})\sqrt{(a_x - b_x)^2 + (a_y - b_y)^2 + (a_z - b_z)^2} = (\dfrac{1}{\sqrt{3}}) |\vec{a} - \vec{b}| \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-f01e9df13bcfeed19b0e82259fad0d42_l3.png "Rendered by QuickLaTeX.com")
It’s also the square root of the dot product of the difference vector  with it self scaled by :
with it self scaled by :
![\[ RMSE(\vec{a}, \vec{b}) = (\dfrac{1}{\sqrt{3}}) |\vec{a} - \vec{b}| = (\dfrac{1}{\sqrt{3}}) \sqrt{(\vec{a} - \vec{b}) \cdot (\vec{a} - \vec{b})} \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-510f0d67d0113a58be8c87d60b4e8345_l3.png "Rendered by QuickLaTeX.com")
Here’s an important property of projection:
The projection of a vector onto another vector is the vector parallel to that has the minimal RMSE with respect to . In other words,  gives you the best scaled version of to approximate .
gives you the best scaled version of to approximate .
Also note that if is larger than , it means has a smaller RMSE than  with respect to ; thus, points in a direction closer to that o than does.
with respect to ; thus, points in a direction closer to that o than does.
Now we’re finished with vectors. It’s time to move onto curves.
“Projecting” a Curve onto Another
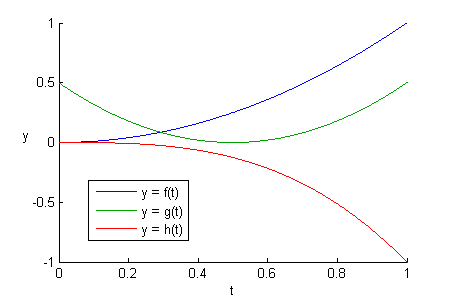
Let’s consider these three curves:

When working with curves, as opposed to vectors, we need to additionally specify an interval of of interest. For simplicity, we will consider  for the rest of this post.
for the rest of this post.
Below is a figure showing what they look like side-by-side within our interval of interest:
Just like vectors, “projecting” a curve  onto another curve
onto another curve  gives you the best scaled version of to approximate , and the “projection” has minimal RMSE with respect to . To compute the RMSE of curves, we need to first figure out how to compute the “dot product” of two curves.
gives you the best scaled version of to approximate , and the “projection” has minimal RMSE with respect to . To compute the RMSE of curves, we need to first figure out how to compute the “dot product” of two curves.
Recall that the dot product of vectors is equal to the sum of component-wise products:
Mirroring that, let’s sum up the products of samples of curves at regular intervals, and we normalize the sum by dividing it with the number of samples, so we don’t get drastically different results due to different number of samples. If we take 10 samples between to compute the dot product of and , we get:
![\[ f(t) \cdot g(t) = \frac{1}{10} \sum_{i = 1}^{10} f(\frac{i}{10}) g(\frac{i}{10}) \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-100eaf5f9c6d8e9ce8689bd418bc6074_l3.png "Rendered by QuickLaTeX.com")
The more samples we use, the more accuracy we get. What if we take an infinite number of samples so we get the most accurate result possible?
![\[ f(t) \cdot g(t) = \lim_{n\to\infty} {\frac{1}{n} \sum_{i = 0}^{n} f(\frac{i}{n}) g(\frac{i}{n}}) \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-1edc237fbff9c4c6f05c3ba0ab93c942_l3.png "Rendered by QuickLaTeX.com")
This basically turns into an integral:
![\[ f(t) \cdot g(t) = \int_{0}^{1} f(t) g(t) dt \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-7cc0947943625acb1c6243795ebb2f4d_l3.png "Rendered by QuickLaTeX.com")
So there we have it, one common definition of the “dot product” of two curves:
The integral of the product of two curves over the interval of interest.
Copying the formula from vectors, the RMSE between two curves and is:
![\[ RMSE(f(t), g(t)) = \sqrt{(f(t) - g(t)) \cdot (f(t) - g(t))} \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-938c3509c36bf5c93b3ff3b3d6bbbe73_l3.png "Rendered by QuickLaTeX.com")
In integral form, it becomes:
![\[ RMSE(f(t), g(t)) = \sqrt{\int_{0}^{1} (f(t) - g(t))^2 dt} \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-b34918303a077278b25ca535ef38086b_l3.png "Rendered by QuickLaTeX.com")
The “mean” part of the error is omitted since it’s a division by 1, the length of our interval of interest.
To find out which one of the “normalized” version of and  has less RMSE with respect to the normalized version of , we take the dot products of the normalized versions of the curves:
has less RMSE with respect to the normalized version of , we take the dot products of the normalized versions of the curves:

The dot product of  and
and  is larger than that of and
is larger than that of and  . That means has a lower RMSE than with respect to .
. That means has a lower RMSE than with respect to .
Drawing analogy from vectors, is conceptually “pointing in a direction” closer to that of than does.
Now let’s try finding the best scaled version of that has minimal RMSE with respect to , by computing the projection of onto :
![\[ proj(f(t), g(t)) = \dfrac{f(t) \cdot g(t)}{g(t) \cdot g(t)} g(t) = \dfrac{4}{3} g(t) = \dfrac{8}{3} (t - \dfrac{1}{2})^2 \]](http://allenchou.net/wp-content/ql-cache/quicklatex.com-b164295bee187bc0c7a4fc2919d59749_l3.png "Rendered by QuickLaTeX.com")
And this is what , , and  look like side-by-side:
look like side-by-side:
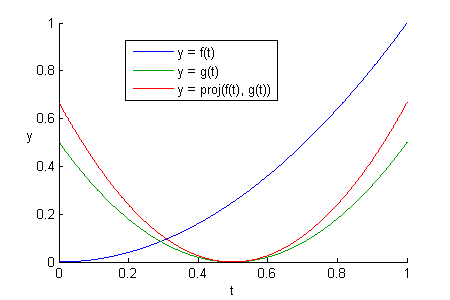
The projected curve is a scaled-up version of that is a better approximation of than itself; it is the best scaled version of that has the least RMSE with respect to .
Now that you know how to “project” a curve onto another, we will see how to approximate a curve with multiple simpler curves while maintaining minimal error.

Great article! Applying linear algebra techniques for function was very clever idea. Now I can see how it is really related to the Fourier transform. Can’t wait to see next part 🙂