原始檔案與未來教學更新資訊可於Patreon取得
您可於Twitter上追蹤我
本文屬於遊戲程式系列文
Here is the original English post.
本文之英文原文在此
簡介
我先前就讀於DigiPen,每逢”公司日”邀請業界人士來學校分享專業經驗,在問與答時間總是會出現一個常駐問題:請告訴我們你希望當初在學校就已學會的事(主題可涵蓋技術能力、社交能力、製作能力等)。我常常想像,若我以校友身分參加”公司日”回母校分享經驗,我會如何回答這個問題。經過了很長一段時間,我心中一直沒有個明確的答案。直到現在,如果我回母校參加”公司日”分享經驗,我大概會針對CS的同學給予這個答覆──我希望我在學校的時候,就能學到兩個遊戲程式的優化技巧:延遲蒐集運算結果(delayed result gathering)和時間切割(time slicing)。
這是我加入頑皮狗(Naughty Dog)之後最先學到的兩個技巧,而且它們在我的職業生涯中非常實用。時至今日,我仍然在不少遊戲系統中使用這兩個優化技巧。它們是相當泛用的解決方案,能廣泛且有效的地套用到各種系統上。
在這個教學中,我會先介紹第一個技巧:延遲蒐集運算結果。我會於下一個教學中再介紹時間切割。
範例:曝光地圖與曝光迴避
首先,來介紹一下作為貫串這兩個教學作為示範基底的範例。在這兩個教學的過程中,我將會不斷地修改這個範例,展示如何將這些優化技巧套用到既有系統上。
這個範例是曝光地圖(exposure map)與曝光迴避(exposure avoidance)。有個網格(grid)資料結構,其每一個格子(cell)存有是否曝光於一個哨兵(sentinel)的資料。另外有一個角色會嘗試避免曝光於哨兵的視野中。若哨兵移動後導致角色所在的格子曝光,角色則會逃離至附近的未曝光格子。這位角色是個害羞的球球。
以下是這個機制(mechanic)的更新迴圈(update loop),共有三個步驟:
- 根據哨兵的位置更新曝光地圖,使用射線投射(raycast)偵測從哨兵眼睛到每一個格子的直線途徑是否淨空。若直線途徑淨空,表示這個格子曝光於哨兵的視野中。
- 計算角色到每一個格子的路徑長度。
- 若角色所在的格子已曝光,更新目的地為附近的未曝光格子,並使角色尋徑至該格子。
此更新迴圈的程式碼看起來如下:
void Update()
{
UpdateExposureMap();
UpdatePathLengths();
UpdateDestination();
}
大學時期的我實作UpdateExposureMap,應該會像這樣:
void UpdateExposureMap()
{
for (int iCell = 0; iCell < NumCells; ++iCell)
{
Vector3 cellCenter = Grid[iCell];
Vector3 vec = cellCenter - EyePos;
Vector3 rayDir = vec.normalized;
float rayLen = vec.magnitude;
bool exposed = !Physics.Raycast(EyePos, rayDir, rayLen);
ExposureMap[iCell] = exposed;
}
}
於這兩個教學的過程中,我將針對步驟1優化,也就是UpdateExposureMap,所以我不會針對步驟2和3多加著墨。要注意的一點是,教學提到的優化技巧不是用來針對特定低階演算法優化(如射線投射本身),而是於較高階的角度來優化這些演算法的呼叫方式。另外,根據實際情況,射線投射有可能不是用來更新曝光地圖的最佳方法,在此使用射線投射純粹是為了教學目的。
上述的實作方式,每禎(frame)進行10k個射線投射,性能分析器(profiler)呈現的結果如下:
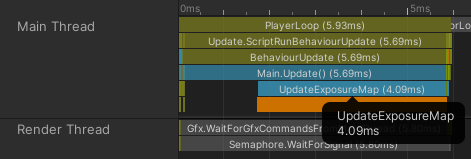
當更加放大時間軸,可以看到那條長橘色區塊其實是許多小塊的射線投射區塊所組成,一個射線投射對應一個小區塊。
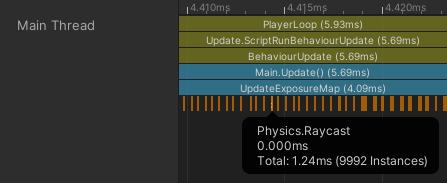
可以馬上觀測到一個問題:大量的射線投射並不便宜。在主執行緒上接連呼叫射線投射函式,將主執行緒的運算資源佔去不少。針對這個問題的優化在所難免。
多執行續 (Multi-Threading)
於主執行續上呼叫一連串的阻擋式(blocking)射線投射函式,結果非常糟糕。射線投射屬於非常容易平行化的運算,每一個射線投射都是做一樣的事情:於空間資料中找尋射線與碰撞體(collider)的碰撞點。每一個射線投射是可以於獨立的執行緒上運算的。與其在主執行緒上進行一連串的射線投射運算,我們可以嘗試將運算卸載到其他的CPU核心上,也就是加以利用多執行緒。如果我們有10個工作核心(worker cores),我們可以嘗試將射線投射分配到10個執行緒上去運算。
Unity的使用者很幸運,因為官方有提供方便實作多執行緒運算的系統:Unity的工作系統(job system)。官方甚至有提供針對多執行緒運算射線投射的工作類別!你只需要設定好射線、設定每一個執行緒要運算多少個射線投射、開始工作,就完工了!射線投射將會分布於多個執行緒上運算,剩下要做的就是等運算結束之後蒐集運算結果。
我們定義兩個工作結構(struct):RaycastSetupJob和RaycastGatherJob。在開始實際的射線投射工作之前,RaycastSetupJob負責設置每個射線的指令,然後RaycastGatherJob負責蒐集射線投射工作的運算結果。工作之間的依賴關係如下:射線投射工作依賴RaycastSetupJob、RaycastGatherJob依賴射線投射工作。
struct RaycastSetupJob : IJobParallelFor
{
public Vector3 EyePos;
[ReadOnly]
public NativeArray<Vector3> Grid;
[WriteOnly]
public NativeArray<RaycastCommand> Commands;
public void Execute(int index)
{
Vector3 cellCenter = Grid[index];
Vector3 vec = cellCenter - EyePos;
Commands[index] =
new RaycastCommand(EyePos, vec.normalized, vec.magnitude);
}
}
struct RaycastGatherJob : IJobParallelFor
{
[ReadOnly]
public NativeArray<RaycastHit> Results;
[WriteOnly]
public NativeArray<bool> ExposureMap;
public void Execute(int index)
{
bool exposed = (Results[index].distance <= 0.0f);
ExposureMap[index] = exposed;
}
}
然後UpdateExposureMap函式被更改如下:
void UpdateExposureMap()
{
// allocate data shared across jobs
var allocator = Allocator.TempJob;
var commands =
new NativeArray<RaycastCommand>(NumCells, allocator);
var results =
new NativeArray<RaycastHit>(NumCells, allocator);
// create setup job
var setupJob = new RaycastSetupJob();
setupJob.EyePos = EyePos;
setupJob.Grid = Grid;
setupJob.Commands = commands;
// create gather job
var gatherJob = new RaycastGatherJob();
gatherJob.Results = results;
gatherJob.ExposureMap = ExposureMap;
// schedule setup job
var hSetupJob = setupJob.Schedule(NumCells, JobBatchSize);
// schedule raycast job
// specify dependency on setup job
var hRaycastJob =
RaycastCommand.ScheduleBatch
(
commands,
results,
JobBatchSize,
hSetupJob
);
// schedule gather job
// specify dependency on raycast job
var hGatherJob =
gatherJob.Schedule(NumCells, JobBatchSize, hRaycastJob);
// kick jobs
JobHandle.ScheduleBatchedJobs();
// wait for completion
hGatherJob.Complete();
// dispose of job data
commands.Dispose();
results.Dispose();
}
這是上述多執行緒實作方法的性能分析結果:
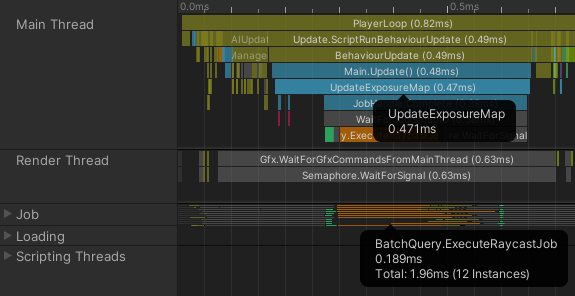
主執行緒被占據的時間縮短了,但仍然因等待於其他CPU核心上執行的工作完成而被佔據了些時間。我們能更進一步地改善這個狀況嗎?
延遲蒐集運算結果 (Delayed Result Gathering)
我開始在頑皮狗工作的前幾天,馬上就得接觸與射線投射相關的系統。一個較資深的工程師帶領我認識這個系統,並不經意給了個小撇步:「不要在開始射線投射運算之後,就讓執行緒浪費時間等運算完成。試著在這一禎開始射線投射運算的工作,然後把運算結果的蒐集延遲到下一禎。」我的腦袋中突然有一個大燈泡亮起來了。這真是太理所當然了!如果遊戲可以負擔得起一禎的延遲運算,那等到下一禎再蒐集運算結果的話,就可以馬上釋出CPU核心的運算資源,以用來運算其他的工作。
若運算結果需要在同一禎內蒐集完畢,仍然可以嘗試在同一禎早些時間點開始運算工作,等到同一禎晚一點的時候再蒐集運算結果。重點是不要在等待運算工作完成的時候佔據主執行緒。
下一個範例迭代,我會開始射線投射工作,並且等到下一禎才蒐集運算結果。如此一來,主執行序上的工作量就只剩下蒐集上一禎的運算結果和開始下一禎才要蒐集結果的運算工作。
運算結果的蒐集改在UpdateExposureMap的開頭。曝光地圖改用雙重緩衝(double-buffered)的方式儲存,射線投射相關工作存取的是後緩衝(back buffer),而剩餘機制邏輯存取的則是前緩衝(front buffer),以避免競爭條件(race condition)。另外,RaycastGatherJob的工作句柄(job handle)與各工作共用的資料將從區域變數(local variable)升格為欄位(field),因為其生命(lifetime)需要行跨2禎。
void UpdateExposureMap()
{
// wait for jobs from last frame to complete
hGatherJob.Complete();
// double-buffering
SwapExposureBackBuffer();
// dispose of data allocated from last frame
if (Commands.IsCreated)
Commands.Dispose();
if (Results.IsCreated)
Results.Dispose();
// allocate data shared across jobs
var allocator = Allocator.TempJob;
Commands =
new NativeArray<RaycastCommand>(NumCells, allocator);
Results =
new NativeArray<RaycastHit>(NumCells, allocator);
// create setup job
var setupJob = new RaycastSetupJob();
setupJob.EyePos = EyePos;
setupJob.Grid = Grid;
setupJob.Commands = Commands;
// create gather job
var gatherJob = new RaycastGatherJob();
gatherJob.Results = Results;
gatherJob.ExposureMap = ExposureMap;
// schedule setup job
var hSetupJob = setupJob.Schedule(NumCells, JobBatchSize);
// schedule raycast job
// specify dependency on setup job
var hRaycastJob =
RaycastCommand.ScheduleBatch
(
Commands,
Results,
JobBatchSize,
hSetupJob
);
// schedule gather job
// specify dependency on raycast job
hGatherJob =
gatherJob.Schedule(NumCells, JobBatchSize, hRaycastJob);
// kick jobs
JobHandle.ScheduleBatchedJobs();
}
這是性能分析的結果:
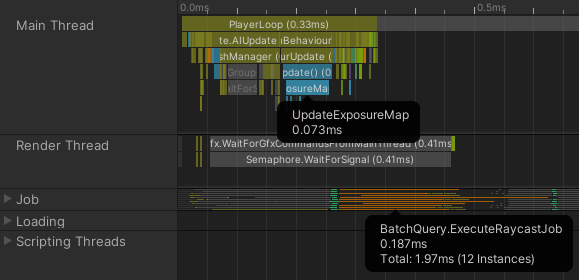
射線投射工作的運算時段已經可以置身UpdateExposureMap時段之外,直到下一禎的UpdateExposureMap才需要蒐集運算結果。如此一來便不會多佔用主執行續了!
結論
我展示了射線投射範例的三階段迭代進化:
- 於主執行續中呼叫一連串的射線投射函式,大幅佔用主執行續的時間。
- 將射線投射的運算移到其他執行緒上,但主執行緒仍然花時間等待工作完成以蒐集結果。
- 主執行緒只用來蒐集上一禎開始的射線投射工作之運算結果,和開始下一禎才需要蒐集結果的射線投射工作。
以下是一些用性能分析器蒐集的數據,我的CPU是Intel i7-8700k,測量的運算量是每禎10k個射線投射。
- 迭代 1 (單執行緒)
主執行緒CPU時間: 4.09ms
繁忙CPU核心平均射線投射運算時間: 1.24ms
所有CPU核心總和射線投射運算時間: 1.24ms - 迭代 2 (多執行緒、同函式中蒐集運算結果)
主執行緒CPU時間: 0.47ms
繁忙CPU核心平均射線投射運算時間: 0.19ms
所有CPU核心總和射線投射運算時間: 1.96ms - 迭代 3 (多執行續、延遲蒐集運算結果)
主執行緒CPU時間: 0.073ms
繁忙CPU核心平均射線投射運算時間: 0.16ms
所有CPU核心總和射線投射運算時間: 1.87ms
儘管迭代 1的總和射線投射運算時間是最低的,多個射線投射函示呼叫的額外支出導致主執行緒CPU時間為4.09ms。而且,迭代 1將所有的運算都塞在同一個CPU核心上,讓其他CPU核心閒置。迭代2 & 3的總和射線投射運算時間大約是1.87-1.96ms,比迭代1的1.24ms還高,原因應該是工作系統本身的額外支出。然而這並不構成問題,因為最重要的數據是繁忙CPU核心的平均運算時間。
迭代2 & 3的平均與總和運算時間幾乎一樣,這是理所當然的,因為兩者只差在蒐集運算結果的時間點。迭代2已經將主執行緒的CPU時間從4.09ms縮短至0.47ms,迭代3則更進一步將時間縮短至0.073ms,這是一個可觀的改進(4.09ms -> 0.073ms)。CPU核心的利用率提升,且每一個核心的平均運算時間遠低於迭代1 (1.24ms -> 0.16ms)。
我在此結束介紹延遲蒐集運算結果優化技巧。於下個教學,我將介紹另一個叫做時間切割的實用技巧,可以更進一步優化本範例的最後一個迭代版本。敬請期待!
若您喜歡這篇教學,請考慮到Patreon支持我。感謝!
