
This post is part of my Game Math Series.
We have seen how to approximate a function using polynomials in this post. A good candidate for polynomial approximation would be the sine function, for it is used a lot in games and is not a cheap function to call. This is essentially the same task as approximating the consine curve, since the cosine curve is just a shifted sine curve.
The sine curve is periodic, so will just focus on the domain 
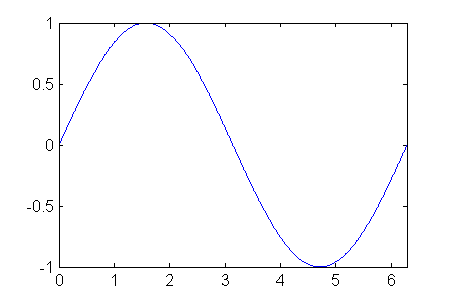
We will first try to match a quarter of the sine curve, a downward “hill”.
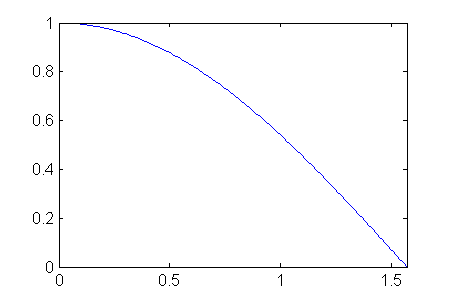
We will impose four conditions, the positions and slopes of the hill top and the hill bottom. This means we have to use a polynomial of degree 3 (a cubic curve) to match this hill.
![\[ P(x) = a_0 + a_1 x + a_2 x^2 + a_3 x^3 \]](https://allenchou.net/wp-content/ql-cache/quicklatex.com-971d211fb409adee1d57593075aad260_l3.png "Rendered by QuickLaTeX.com")
And we get these equations from the four conditions:

where  denotes the first-order derivative of the function
denotes the first-order derivative of the function  .
.
So here’s the system of equations we have to solve in order to obtain the coefficients of the polynomial:

After solving the system of equations, we get:

Let’s do a quick check by plotting the polynomial curve along with the original hill curve on the same figure:
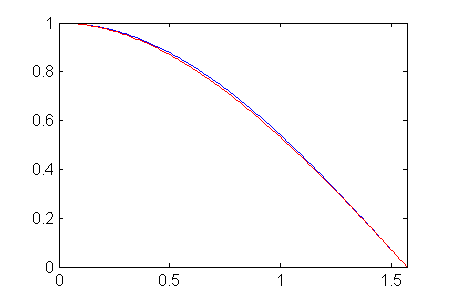
The blue curve is the original hill curve, and the red curve is our polynomial. It looks like they are about the same. Good.
The final step is to copy this hill four times, and piece them together so they make up an approximation of the sine curve.
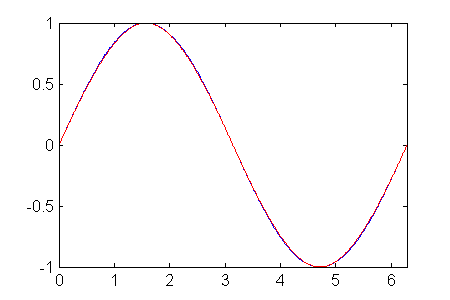
The blue curve is the original sine curve, and the red curve is our four hill curves pieced together. Looking good.
Here’s the C++ code for implementing the faster sine with the polynomial we just derived:
#define PI (3.1415926535f)
#define HALF_PI (0.5f * PI)
#define TWO_PI (2.0f * PI)
#define TWO_PI_INV (1.0f / TWO_PI)
inline float Hill(float x)
{
const float a0 = 1.0f;
const float a2 = 2.0f / PI - 12.0f / (PI * PI);
const float a3 = 16.0f / (PI * PI * PI) - 4.0f / (PI * PI);
const float xx = x * x;
const float xxx = xx * x;
return a0 + a2 * xx + a3 * xxx;
}
float FastSin(float x)
{
// wrap x within [0, TWO_PI)
const float a = x * TWO_PI_INV;
x -= static_cast<int>(a) * TWO_PI;
if (x < 0.0f)
x += TWO_PI;
// 4 pieces of hills
if (x < HALF_PI)
return Hill(HALF_PI - x);
else if (x < PI)
return Hill(x - HALF_PI);
else if (x < 3.0f * HALF_PI)
return -Hill(3.0f * HALF_PI - x);
else
return -Hill(x - 3.0f * HALF_PI);
}
And the cosine curve is just the sine curve shifted by  .
.
float FastCos(float x)
{
return FastSin(x + HALF_PI);
}
The performance gain is about 3.5x on my machine. This is probably not as impressive as some other hacks you may find on the internet, but it’s faster than the original sine function nonetheless. Besides, you get to practice approximating a function using polynomials!
By the way, it is not a good idea to approximate the tangent function using polynomial approximation, because there are points in the function that have infinite slopes. Trying to approximate such functions near the points of infinite slope with polynomials would produce polynomials that fluctuate in grate magnitude. You may approximate the tangent function using the trigonometric identity  with
with  and
and  approximated by polynomials. The performance gain is about 1.5x on my machine using this approach.
approximated by polynomials. The performance gain is about 1.5x on my machine using this approach.

One thing about using LUTs- when they get big they are BAD for cache misses …. OK on small SRAM micros where there is no cache.
For such crucial operations like sine/cosine, I’d get rid of those branches. Maybe something
like this:
The branches were removed, but at the expense of more mults/adds. I don’t know if these mults by 0/1 will be optimized, need to read the generated code/measure etc, but that’s just the idea.
Very nice post though, obtaining complex functions like trig with just a few mults/adds is great! 🙂
I did a quick test on my machine using your code. Looks like the extra multiplications are not faster than the 4 branches. The branch-less implementation is only about 1.5x faster than
std::sinon my machine.I wonder how this compares to a lookup table. http://en.wikipedia.org/wiki/Lookup_table#Computing_sines
I will try implementing the LUT version and compare the results in later posts. Thanks for the input!
Wrapping x is
std::fmod, shouldn’t line 21 bex -= static_cast(a) * TWO_PI?VC++’s implementation of
std::fmodis just about the same speed asstd::sinon my machine, so I avoided using it. And yes, line 21 should bex -= static_cast(a) * TWO_PI . Thanks for pointing it out.