原始檔案與未來教學更新資訊可於Patreon取得
您可於Twitter上追蹤我
本文屬於遊戲程式系列文
Here is the original English post.
本文之英文原文在此
前備教學
簡介
於上一個教學中,我以曝光迴避作為範例來示範如何使用延遲蒐集運算結果的優化技巧。基本概念就是在工作執行緒(worker threads)上開始運算工作,然後等一會兒之後才蒐集運算結果,如此可以避免佔據主執行緒。
如果遊戲可以負擔一禎的延遲,那就可以等到下一禎才蒐集工作運算結果。如果遊戲無法負擔一禎的延遲,仍然可以嘗試在同一禎等待到稍後再蒐集結果。
但如果有工作無法在一禎之內運算完畢,又或有工作需要的運算時間比我們希望的還要長時,該怎麼辦?這時我們可以把工作量分配給多禎,這正是時間切割的核心概念,這是另外一個我從工作中學到且最喜歡的優化技巧之一。
仔細想想,其實時間切割隨處可見。材質串流、無接縫載入等,這些不會拖垮遊戲禎率的”背景運算”都可歸類為時間切割。沒有辦法在一禎之內完成運算,那就多用幾禎來算吧,這是個很單純卻非常有效的做法。
回顧曝光地圖範例
回想上個教學中的曝光地圖範例。有設置射線投射的工作、實際計算射線投射的工作、和蒐集計算結果的工作。曝光地圖的更新函式啟動這些工作,然後於下一禎蒐集計算結果。
以下是各工作的結構:
struct RaycastSetupJob : IJobParallelFor
{
public Vector3 EyePos;
[ReadOnly]
public NativeArray<Vector3> Grid;
[WriteOnly]
public NativeArray<RaycastCommand> Commands;
public void Execute(int index)
{
Vector3 cellCenter = Grid[index];
Vector3 vec = cellCenter - EyePos;
Commands[index] =
new RaycastCommand(EyePos, vec.normalized, vec.magnitude);
}
}
struct RaycastGatherJob : IJobParallelFor
{
[ReadOnly]
public NativeArray<RaycastHit> Results;
[WriteOnly]
public NativeArray<bool> ExposureMap;
public void Execute(int index)
{
bool exposed = (Results[index].distance <= 0.0f);
ExposureMap[index] = exposed;
}
}
這是曝光地圖的更新函式:
id UpdateExposureMap()
{
// wait for jobs from last frame to complete
hGatherJob.Complete();
// double-buffering
SwapExposureBackBuffer();
// dispose of job data allocated from last frame
if (Commands.IsCreated)
Commands.Dispose();
if (Results.IsCreated)
Results.Dispose();
// allocate data shared across jobs
var allocator = Allocator.TempJob;
Commands =
new NativeArray<RaycastCommand>(NumCells, allocator);
Results =
new NativeArray<RaycastHit>(NumCells, allocator);
// create setup job
var setupJob = new RaycastSetupJob();
setupJob.EyePos = EyePos;
setupJob.Grid = Grid;
setupJob.Commands = Commands;
// create gather job
var gatherJob = new RaycastGatherJob();
gatherJob.Results = Results;
gatherJob.ExposureMap = ExposureMap;
// schedule setup job
var hSetupJob = setupJob.Schedule(NumCells, JobBatchSize);
// schedule raycast job
// specify dependency on setup job
var hRaycastJob =
RaycastCommand.ScheduleBatch
(
Commands,
Results,
JobBatchSize,
hSetupJob
);
// schedule gather job
// specify dependency on raycast job
hGatherJob =
gatherJob.Schedule(NumCells, JobBatchSize, hRaycastJob);
// kick jobs
JobHandle.ScheduleBatchedJobs();
}
然後這是性能分析結果:
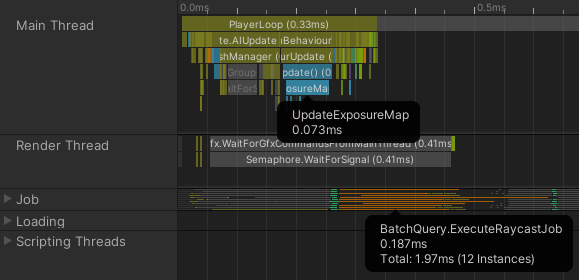
射線投射工作的運算時段可置身於更新函式本體之外,釋放主執行緒任其進行其他運算。
時間切割
現在,我們來看看如何使用時間切割來進一步減少花在射線投射計算的CPU時間。這是我通常使用的時間切割模式:
- 宣告一個代表當前運算進度的引數(index)或迭代器(iterator)。
- 於新一工作批次的開端,將引數初始化。
- 隨著每禎的運算完成,將引數遞增。
- 當前批次的最後一份工作完成時,執行最後收尾的處理邏輯。
- 回到第2步,開始下一個工作批次。
現在我們來修改之前定義的工作結構,好讓它們一次只處理一部份的曝光地圖。
- 增加一個
TimeSliceBaseIndex欄位(初始化為0)用來追蹤時間切割進度。 - 於工作結構中新增一個代表每禎處理的曝光地圖格子範圍開端的引數。
- 將
RcastGatherJob結構中ExposureMap欄位的WriteOnly特性(attribute)改成NativeDisableParallelForRestriction,以移除Unity的安全限制,不然每個工作的Execute函式只能用被傳入的引數來存取陣列元素。
於是工作結構被改成:
struct RaycastSetupJob : IJobParallelFor
{
public Vector3 EyePos;
[ReadOnly]
public NativeArray<Vector3> Grid;
[ReadOnly]
public NativeArray<RaycastCommand> Commands;
public int TimeSliceBaseIndex;
public void Execute(int localIndex)
{
int globalIndex = localIndex + TimeSliceBaseIndex;
Vector3 cellCenter = Grid[globalIndex];
Vector3 vec = cellCenter - EyePos;
Commands[localIndex] =
new RaycastCommand(EyePos, vec.normalized, vec.magnitude);
}
}
struct RaycastGatherJob : IJobParallelFor
{
[ReadOnly]
public NativeArray<RaycastHit> Results;
[NativeDisableParallelForRestriction]
public NativeArray<bool> ExposureMap;
public int TimeSliceBaseIndex;
public void Execute(int localIndex)
{
int globalIndex = localIndex + TimeSliceBaseIndex;
bool exposed = (Results[localIndex].distance <= 0.0f);
ExposureMap[globalIndex] = exposed;
}
}
然後這是新的更新函式:
void UpdateExposureMap(int numRaysPerTimeSlice)
{
// wait for jobs from last frame to complete
hGatherJob.Complete();
// trim excess ray count for the last time slice of batch
int numExcessRays =
TimeSliceBaseIndex + numRaysPerTimeSlice - NumCells;
numRaysPerTimeSlice -= Mathf.Max(0, numExcessRays);
// batch ended?
if (TimeSliceBaseIndex < 0)
{
// double-buffering
SwapExposureBackBuffer();
// reset time slicing index
TimeSliceBaseIndex = 0;
}
// dispose of job data allocated from last frame
if (Commands.IsCreated)
Commands.Dispose();
if (Results.IsCreated)
Results.Dispose();
// allocate data shared across jobs
var allocator = Allocator.TempJob;
Commands =
new NativeArray<RaycastCommand>
(
numRaysPerTimeSlice,
allocator
);
Results =
new NativeArray<RaycastHit>
(
numRaysPerTimeSlice,
allocator
);
// create setup job
var setupJob = new RaycastSetupJob();
setupJob.EyePos = EyePos;
setupJob.Grid = Grid;
setupJob.Commands = Commands;
setupJob.TimeSliceBaseIndex = TimeSliceBaseIndex;
// create gather job
var gatherJob = new RaycastGatherJob();
gatherJob.Results = Results;
gatherJob.ExposureMap = ExposureMap;
gatherJob.TimeSliceBaseIndex = TimeSliceBaseIndex;
// schedule setup job
var hSetupJob =
setupJob.Schedule
(
numRaysPerTimeSlice,
JobBatchSize
);
// schedule raycast job
// specify dependency on setup job
var hRaycastJob =
RaycastCommand.ScheduleBatch
(
Commands,
Results,
JobBatchSize,
hSetupJob
);
// schedule gather job
// specify dependency on raycast job
hGatherJob =
gatherJob.Schedule
(
numRaysPerTimeSlice,
JobBatchSize,
hRaycastJob
);
// advance time slice index
TimeSliceBaseIndex += numRaysPerTimeSlice;
// end of batch?
if (TimeSliceBaseIndex >= NumCells)
{
// signal end of batch
TimeSliceBaseIndex = -1;
}
// kick jobs
JobHandle.ScheduleBatchedJobs();
}
如果我們將每禎的射線投射量設為總數的10%,那就需要10禎來完成一個工作批次,並且觸發一次曝光地圖的緩衝替換(buffer swap)。以下影片中,你可以看到每一個批次的射線投射完成之後,曝光地圖才被刷新一次。影片使用較低的禎率,好讓每禎繪製的除錯資訊停留久一點,以正常禎率來看的話,曝光地圖的刷新延遲並不會這麼長。
若能保證蒐集運算結果時不會有競爭條件,那其實可以不用雙重緩衝,在蒐集運算結果的時候更新單一的曝光地圖資料。如此一來,蒐集結果的同一禎就會更新相對應的曝光地圖區塊,整體系統的反應速度會上升。
至於效能,以下為於不同程度的時間切割進行每批次10k個射線投射的數據(搭配延遲蒐集運算結果):
- 沒有時間切割:
主執行緒CPU時間: 0.073ms
繁忙CPU核心平均射線投射運算時間: 0.156ms
所有CPU核心總和射線投射運算時間: 1.87ms
曝光地圖刷新延遲: 1禎 - 每禎計算50%射線投射:
主執行緒CPU時間: 0.058ms
繁忙CPU核心平均射線投射運算時間: 0.093ms
所有CPU核心總和射線投射運算時間: 1.11ms
曝光地圖刷新延遲: 2禎 - 每禎計算10%射線投射
主執行緒CPU時間: 0.044ms
繁忙CPU核心平均射線投射運算時間: 0.018ms
所有CPU核心總和射線投射運算時間: 0.21ms
曝光地圖刷新延遲: 10禎
隨著時間切割程度增加,主執行緒的CPU時間稍微降低。射線投射的CPU核心運算時間大致與每禎的射線量成正比。
結論
我示範了如何用時間切割將工作分配到多禎執行。使用時間切割,可以很自由地在運算時間預算與更新延遲程度之間找尋平衡點。
若你熟悉Unity的coroutine,那你可能有想過能利用coroutine實作時間切割,利用yield來暫時中斷工作並於下一禎繼續。技術上來說,這的確算是時間切割,但要注意Unity的coroutine只會在主執行緒上執行,並不會利用工作執行緒,所以coroutine執行時其實是在佔據主執行緒的。強烈建議盡量使用所有的CPU核心,讓主執行緒的工作量越少越好。
若您喜歡這篇教學,請考慮到Patreon支持我。感謝!
